The quadratic complexity of Multimodal Large Language Models (MLLMs) with respect to context length poses significant computational and memory challenges, hindering their real-world deployment.
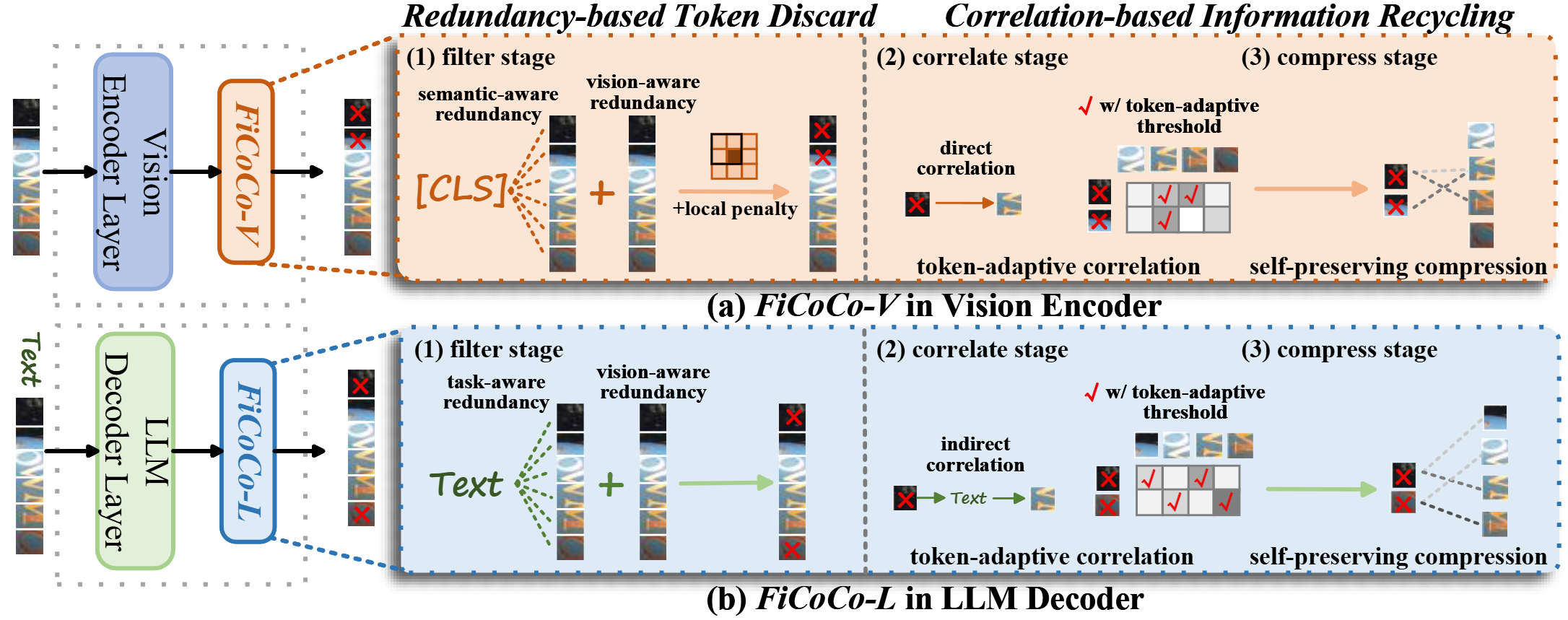
In the paper, we devise a ''filter-correlate-compress'' framework to accelerate the MLLM by systematically optimizing multimodal context length during prefilling. The framework first implements FiCoCo-V, a training-free method operating within the vision encoder.
It employs a redundancy-based token discard mechanism that uses a novel integrated metric to accurately filter out redundant visual tokens.
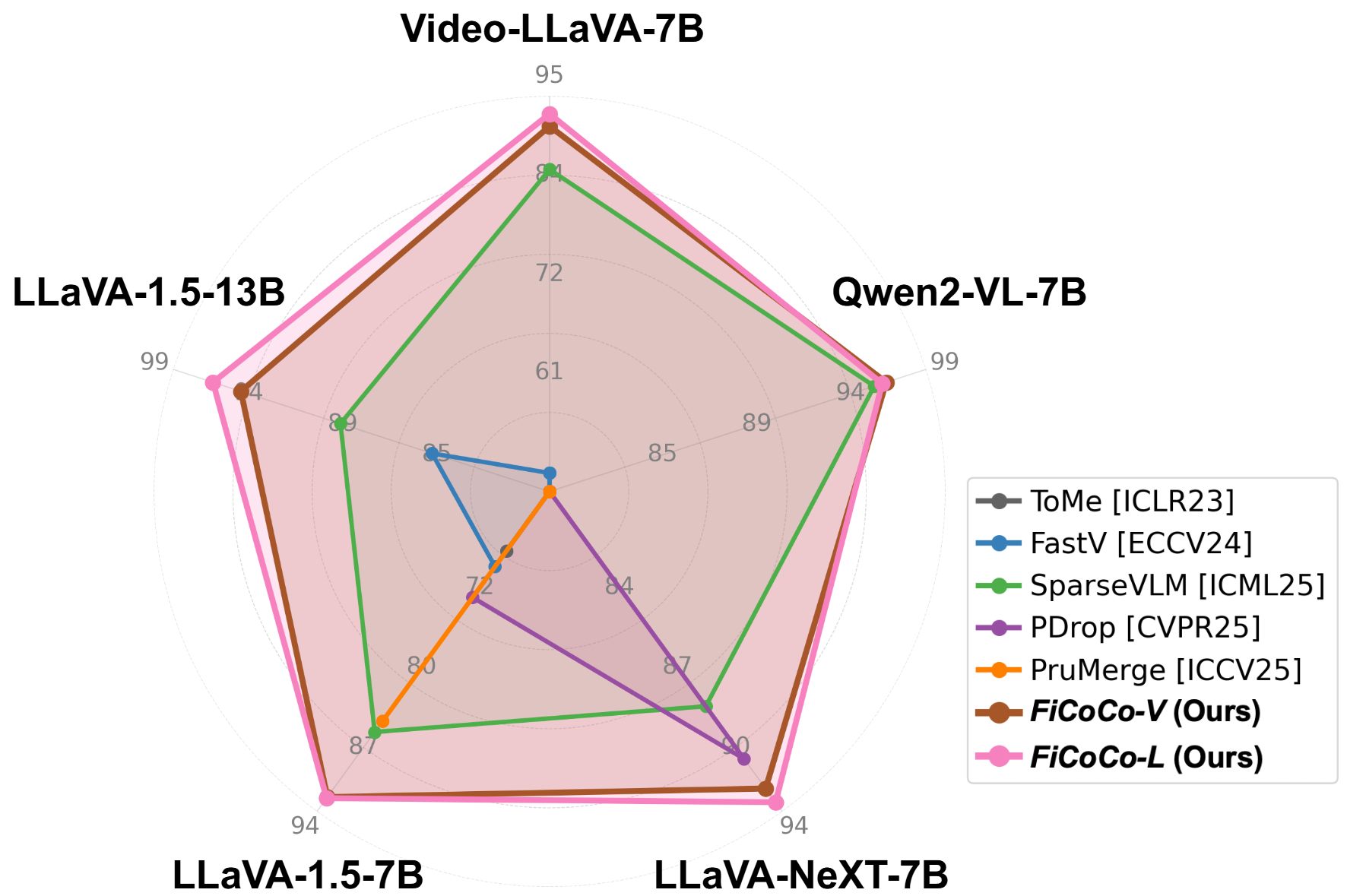
To mitigate information loss, the framework introduces a correlation-based information recycling mechanism that allows preserved tokens to selectively recycle information from correlated discarded tokens with a self-preserving compression, thereby preventing the dilution of their own core content. The framework's FiCoCo-L variant further leverages task-aware textual priors to perform token reduction directly within the LLM decoder. Extensive experiments demonstrate that the FiCoCo series effectively accelerates a range of MLLMs, achieves up to 14.7x FLOPs reduction with 93.6% performance retention. Our methods consistently outperform state-of-the-art training-free approaches, showcasing effectiveness and generalizability across model architectures, sizes, and tasks without requiring retraining.